Website
¿Cómo un dominio vencido nos enseñó a monitorear webs de clientes de forma diferente?
Descubre cómo la caída del dominio de un sitio web nos llevó a crear una herramienta de monitoreo / uptime con IA para detectar incidentes más rápido, entender si el problema era local o global.
Descubre cómo la caída del dominio de un sitio web nos llevó a crear una herramienta de monitoreo / uptime con IA para detectar incidentes más rápido, entender si el problema era local o global.
Alejandro Duarte
Alejandro Duarte

Todo comenzó mientras revisábamos el reporte de rendimiento web de un cliente. Era una de esas tareas rutinarias que forman parte del día a día y que, en teoría, no deberían traer sorpresas. Pero al intentar entrar al sitio para validar algunos puntos, nos encontramos con algo inesperado: la web no cargaba. No estaba lenta, ni presentaba un error puntual. Estaba totalmente caída.
En ese momento entendimos algo esencial: la caída de un sitio puede ocurrir. Lo que no debería ocurrir es que el equipo encargado de la salud técnica de la web no la detecte con anticipación.
Eso afecta directamente la percepción del servicio, la capacidad de respuesta del equipo y, sobre todo, la confianza. Cuando hay una falla en la web, también se compromete la operatividad del negocio, que al final es lo que más le importa al cliente. Si un usuario entra y encuentra el sitio caído, la percepción sobre la calidad del servicio que ofrece la marca se ve seriamente afectada. Afortunadamente, no llegamos a ese punto.
Al investigar lo que había sucedido, descubrimos que no se trataba de un fallo de despliegue, ni de una caída general del hosting, ni de un problema de rendimiento. La causa era más simple de lo que esperábamos y, justamente por eso, más fácil de pasar por alto: la tarjeta asociada al pago automático del dominio había fallado, el dominio venció y GoDaddy lo dio de baja.
Lo más frustrante fue confirmar que sí había señales previas. En su guía “11 truths about buying a domain name in Australia”, GoDaddy explica que envía varios correos de aviso durante los 30 días previos y los 30 días posteriores a la expiración del dominio, además de recomendar la renovación automática y mantener actualizado el método de pago. Es decir, la alerta existía. El problema fue que quedó perdida entre otros correos y no la vimos a tiempo.
Dentro del equipo, esta experiencia nos dejó una sensación incómoda, pero también una reflexión valiosa. Más allá del incidente puntual, nos obligó a hacernos una pregunta: ¿qué debería tener un sistema de monitoreo realmente útil para una agencia que administra múltiples sitios de clientes, cada uno con su propio stack, su propio dominio, distintos responsables y distintos puntos de falla?
A partir de la pregunta empezamos a ver el problema desde otro enfoque. No como un simple monitoreo de uptime, sino como una capa de visibilidad y control que nos permitiera anticiparnos, entender mejor lo que está pasando y responder con el nivel de servicio que queremos dar.
Las herramientas de uptime web no siempre resuelven lo que una startup necesita
Las herramientas que ya existen en el mercado son buenas y cumplen bien su función. Pingdom, por ejemplo, ofrece monitoreo sintético y supervisa disponibilidad desde más de 100 ubicaciones globales. Better Stack reúne monitoreo, gestión de incidentes, guardias y páginas de estado en una misma plataforma, y además permite configurar alertas para la expiración de dominios. UptimeRobot, por su parte, ha fortalecido la gestión de grandes volúmenes de monitores con funciones pensadas para organizar servicios relacionados y revisar su estado de forma más clara.
Nuestro problema no era que estas plataformas fueran insuficientes. El problema era otro. Necesitábamos entender, en un solo lugar, qué sitios estaban activos, dónde estaban alojados, quién administraba el dominio, cuándo vencía, si una caída era aislada o formaba parte de un problema más amplio, y qué debía hacer el equipo apenas llegara una alerta. En otras palabras, necesitábamos traducir señales técnicas en contexto operativo.
Porque cuando gestionas 30, 40 u 80 sitios de clientes, el trabajo real empieza cuando tienes que responder, casi al mismo tiempo, varias preguntas clave: ¿qué pasó?, ¿a quién afecta?, ¿el problema es nuestro?, ¿viene del proveedor? ¿conviene escalarlo de inmediato o esperar?
Esa experiencia fue la que nos llevó a crear nuestra propia herramienta, NoodleSoup Monitor, pensada justamente para responder esas preguntas con rapidez y claridad. Más adelante, en las siguientes secciones, explicaremos con más detalle cómo funciona.
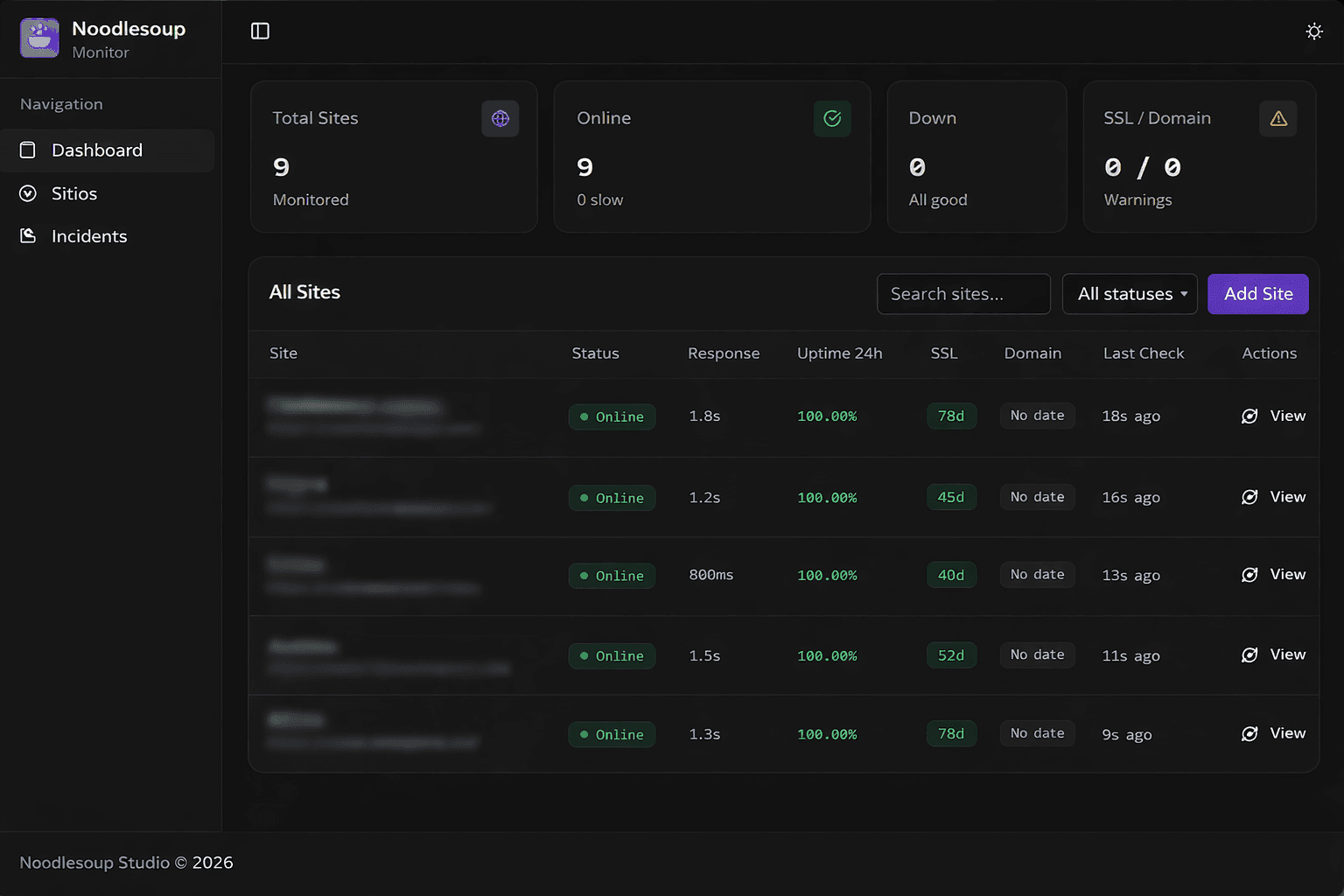
Así nació NoodleSoup Monitor
Después de aquel incidente con el dominio, decidimos dejar de depender solo de una combinación de correos y de la memoria del equipo. Por eso construimos, con Replit, una herramienta interna a la que llamamos NoodleSoup Monitor.
La primera función fue crear un dashboard con todas las webs activas de nuestros clientes. No solo la URL, sino también el hosting (en muchos casos, Framer), el proveedor del dominio y la fecha de vencimiento. Queríamos que el equipo pudiera mirar ese panel y entender, sin abrir diez pestañas, el panorama operativo completo de la cartera.
La segunda función fue habilitar alertas automáticas cada vez que un sitio se cae.
La tercera fue la que realmente marcó la diferencia. Cuando el sistema detecta una caída, no se limita a enviar una alerta. La inteligencia artificial analiza el contexto e identifica patrones para entender qué puede estar ocurriendo. Si varios sitios alojados en la misma plataforma fallan al mismo tiempo, interpreta que podría tratarse de una incidencia compartida. Si la caída parece aislada, la clasifica como un problema potencialmente local. Y si detecta señales externas consistentes con una disrupción mayor, envía una alerta al equipo.
En otras palabras, intentamos automatizar la primera parte del diagnóstico, el tramo inicial, que es justamente donde más tiempo se pierde.
La cuarta función fue cerrar el ciclo de comunicación interna. Cada incidente genera un correo de resumen para el equipo, con una explicación breve de lo que pasó, de lo que se detectó y de cuál parece ser el siguiente paso más razonable. Suena básico, pero era exactamente lo que necesitábamos: claridad y capacidad de reacción para resolver el problema de forma más eficiente.
Cuidar el uptime y la operación web ya forma parte del servicio de una startup
La lección más importante fue entender que las agencias modernas ya no solo diseñan y desarrollan. También cuidan la operación continua de ese mismo producto digital.
Si una web forma parte del motor de demanda de un cliente, entonces monitorearla bien también es parte del servicio. Igual que revisar el performance, detectar errores críticos o entender las dependencias del sistema.
Sobre todo hoy, cuando buena parte del stack depende de proveedores externos y una caída puede empezar por algo tan grande como un incidente de infraestructura o tan pequeño como una tarjeta vencida que nadie vio venir.
También aprendimos algo aún más valioso. Hoy ya podemos desarrollar internamente herramientas capaces de resolver fricciones operativas, automatizar procesos y dar soporte a necesidades concretas del equipo. Con la IA, entornos como Replit y una necesidad operativa bien definida, ya no siempre hace falta esperar a que una herramienta del mercado refleje exactamente tu forma de trabajar. A veces tiene más sentido construir esa herramienta por cuenta propia. Porque proteger el trabajo que haces con tus clientes y elevar la calidad del servicio que les das vale la pena.
El verdadero impacto del uptime web: confianza del cliente y ventas
Cuando trabajas con el sitio web de un cliente, sobre todo en SaaS B2B, el uptime suele tratarse como un asunto de infraestructura. Pero, en realidad, impacta algo mucho más visible para el negocio: la continuidad de la demanda, la entrada de leads, las campañas activas y las oportunidades de venta.
El Annual Outage Analysis 2024 de Uptime Institute muestra que el 54% de los encuestados afirmó que su interrupción significativa más reciente costó más de 100.000 dólares, y un 16% reportó pérdidas superiores a 1.000.000.
Además, el resumen ejecutivo estima que cada año se producen, en promedio, entre 10 y 20 caídas de alto perfil que generan pérdidas financieras importantes, interrupciones operativas y daño reputacional.
Aun así, la lección es la misma. Cuando la web de un cliente cae, importa poco si el origen fue un problema de DNS, una tarjeta vencida, un proveedor externo o un bug. Lo esencial es que alguien del equipo lo detecte rápido, entienda la causa y lo comunique con claridad para actuar a tiempo. Y esa parte, aunque parezca básica, no siempre se resuelve con una herramienta genérica.
Parte de la inspiración para construir NoodleSoup Monitor vino del comentario de un amigo
Él ya había pasado por una situación similar con su sitio web. Su observación fue muy clara: “el sistema debería poder decirte si la caída es tuya o si medio internet se está incendiando”. Y sí, tenía razón.
Al revisar casos de estudio encontramos uno de Cloudflare, en junio de 2024. La compañía explicó que dos eventos independientes provocaron aumentos de latencia y errores durante 114 minutos. En el punto más crítico del incidente, entre el 1,4% y el 2,1% de las solicitudes HTTP al CDN recibieron una página de error genérica, mientras que la latencia p99 de Time To First Byte casi se triplicó. La causa fue una combinación de tráfico mal reenrutado y un bug latente que salió a la luz con un nuevo mecanismo de mitigación DDoS.
Llevado al día a día de una agencia si varios sitios de clientes dependen de una misma capa de infraestructura y varios empiezan a fallar casi al mismo tiempo, necesitas detectar ese patrón de inmediato. No solo para actuar mejor, sino para no perder tiempo revisando configuraciones locales cuando el problema puede ser superficial.
Con Vercel ocurrió algo parecido en agosto de 2024. Su actualización oficial describe una interrupción de 26 minutos en Edge Middleware y Edge Functions, causada por un proveedor upstream que entró en un estado global de configuración errónea. El impacto fue importante: el 61% de todas las invocaciones se vio afectado. Y aunque no todas las partes de la plataforma fallaron en todos los casos, para muchos equipos el síntoma visible fue el mismo de siempre: “la web no funciona”.
Para una agencia, eso cambia por completo el protocolo de respuesta. Si el incidente es global, el siguiente paso es validar el alcance, documentar lo que está pasando, avisar al cliente con claridad y proteger la relación mientras el proveedor resuelve el problema, como mencionamos anteriormente.
¿Cómo puede ayudarte NoodleSoup?
En NoodleSoup trabajamos para que la operación digital de cada sitio sea más clara, más proactiva y menos dependiente de la suerte. Acompañamos a tu equipo desde la estructura del sitio hasta el monitoreo y la respuesta, para crear experiencias web que no solo se vean bien, sino que también estén preparadas para sostenerse en el tiempo.
Todo comenzó mientras revisábamos el reporte de rendimiento web de un cliente. Era una de esas tareas rutinarias que forman parte del día a día y que, en teoría, no deberían traer sorpresas. Pero al intentar entrar al sitio para validar algunos puntos, nos encontramos con algo inesperado: la web no cargaba. No estaba lenta, ni presentaba un error puntual. Estaba totalmente caída.
En ese momento entendimos algo esencial: la caída de un sitio puede ocurrir. Lo que no debería ocurrir es que el equipo encargado de la salud técnica de la web no la detecte con anticipación.
Eso afecta directamente la percepción del servicio, la capacidad de respuesta del equipo y, sobre todo, la confianza. Cuando hay una falla en la web, también se compromete la operatividad del negocio, que al final es lo que más le importa al cliente. Si un usuario entra y encuentra el sitio caído, la percepción sobre la calidad del servicio que ofrece la marca se ve seriamente afectada. Afortunadamente, no llegamos a ese punto.
Al investigar lo que había sucedido, descubrimos que no se trataba de un fallo de despliegue, ni de una caída general del hosting, ni de un problema de rendimiento. La causa era más simple de lo que esperábamos y, justamente por eso, más fácil de pasar por alto: la tarjeta asociada al pago automático del dominio había fallado, el dominio venció y GoDaddy lo dio de baja.
Lo más frustrante fue confirmar que sí había señales previas. En su guía “11 truths about buying a domain name in Australia”, GoDaddy explica que envía varios correos de aviso durante los 30 días previos y los 30 días posteriores a la expiración del dominio, además de recomendar la renovación automática y mantener actualizado el método de pago. Es decir, la alerta existía. El problema fue que quedó perdida entre otros correos y no la vimos a tiempo.
Dentro del equipo, esta experiencia nos dejó una sensación incómoda, pero también una reflexión valiosa. Más allá del incidente puntual, nos obligó a hacernos una pregunta: ¿qué debería tener un sistema de monitoreo realmente útil para una agencia que administra múltiples sitios de clientes, cada uno con su propio stack, su propio dominio, distintos responsables y distintos puntos de falla?
A partir de la pregunta empezamos a ver el problema desde otro enfoque. No como un simple monitoreo de uptime, sino como una capa de visibilidad y control que nos permitiera anticiparnos, entender mejor lo que está pasando y responder con el nivel de servicio que queremos dar.
Las herramientas de uptime web no siempre resuelven lo que una startup necesita
Las herramientas que ya existen en el mercado son buenas y cumplen bien su función. Pingdom, por ejemplo, ofrece monitoreo sintético y supervisa disponibilidad desde más de 100 ubicaciones globales. Better Stack reúne monitoreo, gestión de incidentes, guardias y páginas de estado en una misma plataforma, y además permite configurar alertas para la expiración de dominios. UptimeRobot, por su parte, ha fortalecido la gestión de grandes volúmenes de monitores con funciones pensadas para organizar servicios relacionados y revisar su estado de forma más clara.
Nuestro problema no era que estas plataformas fueran insuficientes. El problema era otro. Necesitábamos entender, en un solo lugar, qué sitios estaban activos, dónde estaban alojados, quién administraba el dominio, cuándo vencía, si una caída era aislada o formaba parte de un problema más amplio, y qué debía hacer el equipo apenas llegara una alerta. En otras palabras, necesitábamos traducir señales técnicas en contexto operativo.
Porque cuando gestionas 30, 40 u 80 sitios de clientes, el trabajo real empieza cuando tienes que responder, casi al mismo tiempo, varias preguntas clave: ¿qué pasó?, ¿a quién afecta?, ¿el problema es nuestro?, ¿viene del proveedor? ¿conviene escalarlo de inmediato o esperar?
Esa experiencia fue la que nos llevó a crear nuestra propia herramienta, NoodleSoup Monitor, pensada justamente para responder esas preguntas con rapidez y claridad. Más adelante, en las siguientes secciones, explicaremos con más detalle cómo funciona.
Así nació NoodleSoup Monitor
Después de aquel incidente con el dominio, decidimos dejar de depender solo de una combinación de correos y de la memoria del equipo. Por eso construimos, con Replit, una herramienta interna a la que llamamos NoodleSoup Monitor.
La primera función fue crear un dashboard con todas las webs activas de nuestros clientes. No solo la URL, sino también el hosting (en muchos casos, Framer), el proveedor del dominio y la fecha de vencimiento. Queríamos que el equipo pudiera mirar ese panel y entender, sin abrir diez pestañas, el panorama operativo completo de la cartera.
La segunda función fue habilitar alertas automáticas cada vez que un sitio se cae.
La tercera fue la que realmente marcó la diferencia. Cuando el sistema detecta una caída, no se limita a enviar una alerta. La inteligencia artificial analiza el contexto e identifica patrones para entender qué puede estar ocurriendo. Si varios sitios alojados en la misma plataforma fallan al mismo tiempo, interpreta que podría tratarse de una incidencia compartida. Si la caída parece aislada, la clasifica como un problema potencialmente local. Y si detecta señales externas consistentes con una disrupción mayor, envía una alerta al equipo.
En otras palabras, intentamos automatizar la primera parte del diagnóstico, el tramo inicial, que es justamente donde más tiempo se pierde.
La cuarta función fue cerrar el ciclo de comunicación interna. Cada incidente genera un correo de resumen para el equipo, con una explicación breve de lo que pasó, de lo que se detectó y de cuál parece ser el siguiente paso más razonable. Suena básico, pero era exactamente lo que necesitábamos: claridad y capacidad de reacción para resolver el problema de forma más eficiente.
Cuidar el uptime y la operación web ya forma parte del servicio de una startup
La lección más importante fue entender que las agencias modernas ya no solo diseñan y desarrollan. También cuidan la operación continua de ese mismo producto digital.
Si una web forma parte del motor de demanda de un cliente, entonces monitorearla bien también es parte del servicio. Igual que revisar el performance, detectar errores críticos o entender las dependencias del sistema.
Sobre todo hoy, cuando buena parte del stack depende de proveedores externos y una caída puede empezar por algo tan grande como un incidente de infraestructura o tan pequeño como una tarjeta vencida que nadie vio venir.
También aprendimos algo aún más valioso. Hoy ya podemos desarrollar internamente herramientas capaces de resolver fricciones operativas, automatizar procesos y dar soporte a necesidades concretas del equipo. Con la IA, entornos como Replit y una necesidad operativa bien definida, ya no siempre hace falta esperar a que una herramienta del mercado refleje exactamente tu forma de trabajar. A veces tiene más sentido construir esa herramienta por cuenta propia. Porque proteger el trabajo que haces con tus clientes y elevar la calidad del servicio que les das vale la pena.
El verdadero impacto del uptime web: confianza del cliente y ventas
Cuando trabajas con el sitio web de un cliente, sobre todo en SaaS B2B, el uptime suele tratarse como un asunto de infraestructura. Pero, en realidad, impacta algo mucho más visible para el negocio: la continuidad de la demanda, la entrada de leads, las campañas activas y las oportunidades de venta.
El Annual Outage Analysis 2024 de Uptime Institute muestra que el 54% de los encuestados afirmó que su interrupción significativa más reciente costó más de 100.000 dólares, y un 16% reportó pérdidas superiores a 1.000.000.
Además, el resumen ejecutivo estima que cada año se producen, en promedio, entre 10 y 20 caídas de alto perfil que generan pérdidas financieras importantes, interrupciones operativas y daño reputacional.
Aun así, la lección es la misma. Cuando la web de un cliente cae, importa poco si el origen fue un problema de DNS, una tarjeta vencida, un proveedor externo o un bug. Lo esencial es que alguien del equipo lo detecte rápido, entienda la causa y lo comunique con claridad para actuar a tiempo. Y esa parte, aunque parezca básica, no siempre se resuelve con una herramienta genérica.
Parte de la inspiración para construir NoodleSoup Monitor vino del comentario de un amigo
Él ya había pasado por una situación similar con su sitio web. Su observación fue muy clara: “el sistema debería poder decirte si la caída es tuya o si medio internet se está incendiando”. Y sí, tenía razón.
Al revisar casos de estudio encontramos uno de Cloudflare, en junio de 2024. La compañía explicó que dos eventos independientes provocaron aumentos de latencia y errores durante 114 minutos. En el punto más crítico del incidente, entre el 1,4% y el 2,1% de las solicitudes HTTP al CDN recibieron una página de error genérica, mientras que la latencia p99 de Time To First Byte casi se triplicó. La causa fue una combinación de tráfico mal reenrutado y un bug latente que salió a la luz con un nuevo mecanismo de mitigación DDoS.
Llevado al día a día de una agencia si varios sitios de clientes dependen de una misma capa de infraestructura y varios empiezan a fallar casi al mismo tiempo, necesitas detectar ese patrón de inmediato. No solo para actuar mejor, sino para no perder tiempo revisando configuraciones locales cuando el problema puede ser superficial.
Con Vercel ocurrió algo parecido en agosto de 2024. Su actualización oficial describe una interrupción de 26 minutos en Edge Middleware y Edge Functions, causada por un proveedor upstream que entró en un estado global de configuración errónea. El impacto fue importante: el 61% de todas las invocaciones se vio afectado. Y aunque no todas las partes de la plataforma fallaron en todos los casos, para muchos equipos el síntoma visible fue el mismo de siempre: “la web no funciona”.
Para una agencia, eso cambia por completo el protocolo de respuesta. Si el incidente es global, el siguiente paso es validar el alcance, documentar lo que está pasando, avisar al cliente con claridad y proteger la relación mientras el proveedor resuelve el problema, como mencionamos anteriormente.
¿Cómo puede ayudarte NoodleSoup?
En NoodleSoup trabajamos para que la operación digital de cada sitio sea más clara, más proactiva y menos dependiente de la suerte. Acompañamos a tu equipo desde la estructura del sitio hasta el monitoreo y la respuesta, para crear experiencias web que no solo se vean bien, sino que también estén preparadas para sostenerse en el tiempo.
Estrategias de branding y web para SaaS, directo a tu inbox
Un email semanal con lo que aprendemos trabajando con startups B2B. Sin relleno.
Acerca de nosotros
Acerca de nosotros
El estudio fue fundado en 2022 por Alejandro Duarte, diseñador multidisciplinario con más de 10 años de experiencia en la creación de productos digitales premiados y en colaborar con marcas de la Fortune 500. Junto a Sasha Briceño, directora creativa híbrida con formación en comunicación social que combina su pasión por las imágenes, el pensamiento estratégico y el storytelling, para crear universos de marca verbales y visuales consistentes. En Noodlesoup, somos un equipo apasionado por el buen diseño y comprometido con proyectos que tienen un propósito significativo. La colaboración, entre el equipo y con nuestros clientes, está en el corazón de todo lo que hacemos: es el umami* que nos caracteriza.
*Japonés: Conocido como el quinto sabor, es uno de los gustos básicos junto con el dulce, el ácido, el amargo y el salado. También significa sabroso.

