IA
¿Cómo proteger tu contenido sin sacrificar visibilidad en IA Overviews?
Aprende a controlar bots de IA y crawlers sin perder visibilidad en Google, AI Overviews y búsquedas dentro de Claude, ChatGPT, Gemini, Perplexity, etc. Descubre cómo usar robots.txt, WAF, CDN y logs para permitir bots de búsqueda como Googlebot y OAI-SearchBot, y bloquear bots de entrenamiento como GPTBot o Google-Extended.
Aprende a controlar bots de IA y crawlers sin perder visibilidad en Google, AI Overviews y búsquedas dentro de Claude, ChatGPT, Gemini, Perplexity, etc. Descubre cómo usar robots.txt, WAF, CDN y logs para permitir bots de búsqueda como Googlebot y OAI-SearchBot, y bloquear bots de entrenamiento como GPTBot o Google-Extended.
Alejandro Duarte
Alejandro Duarte

¿Por qué actualmente es valioso para un SaaS B2B?
Los sistemas de búsqueda con IA por ejemplo: experiencias como AI Overviews o búsquedas dentro de asistentes de IA generativa (herramientas que crean respuestas en lenguaje natural a partir de múltiples fuentes) ya están seleccionando y mostrando enlaces a sitios web.
En la documentación de AI features de Google Search, explica que las IA Overviews muestran enlaces relevantes para ayudar al usuario a explorar mejor un tema, y que esto puede convertirse en un canal real de descubrimiento de marca y de tráfico cualificado para los Saas B2B.
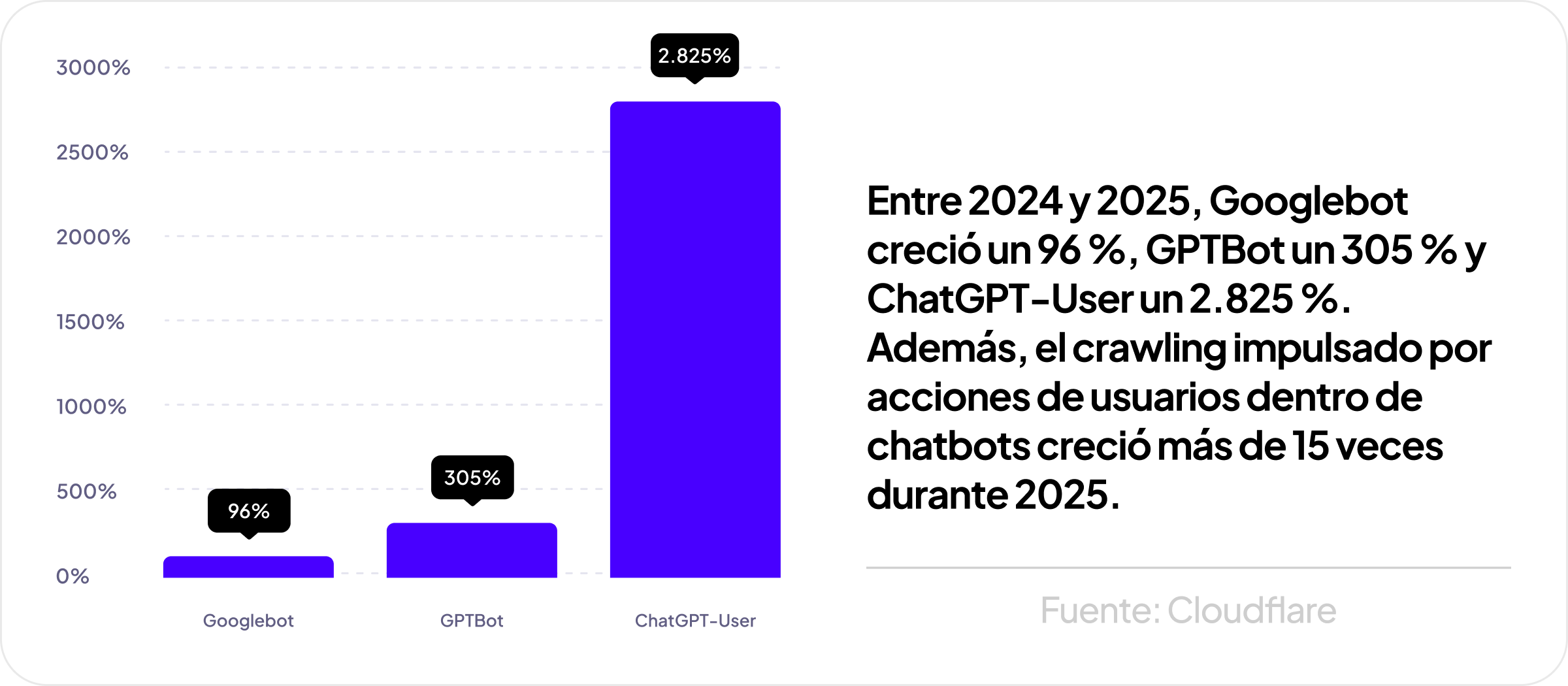
Google también afirma haber observado que, cuando los usuarios hacen clic en resultados con AI Overviews, esos clics suelen ser de mayor calidad, por ejemplo, con más tiempo de permanencia en el sitio. Según Cloudflare, el tráfico conjunto de crawlers de búsqueda e IA creció un 18 % entre mayo de 2024 y mayo de 2025.
¿Qué es el Web Application Firewall (WAF)?
El Web Application Firewall (WAF, o firewall de aplicaciones web) es una capa de protección que se pone en tu sitio web para filtrar y monitorear el tráfico HTTP (las solicitudes que llegan a una web) antes de que alcance tu aplicación.
Su función es permitir, bloquear, desafiar o aplicar rate limiting (limitar cuántas solicitudes puede hacer una misma fuente en un periodo de tiempo) según factores como la IP, el país, patrones de ataque, el user-agent (la identificación que un navegador o bot envía al hacer una solicitud) o señales de comportamiento automatizado.
El WAF es una de las capas que más fácilmente puede romper una estrategia de visibilidad para los motores de IA generativa. Puedes haber permitido un bot en robots.txt (explicaremos el concepto más adelante), pero, si el WAF lo desafía o lo bloquea con una regla anti-bot, ese crawler igual no va a entrar.
Por eso, lo recomendable es no solo permitir OAI-SearchBot en robots.txt, sino también autorizar solicitudes desde los rangos de IP publicados, si quieres aparecer en resultados de búsqueda dentro de Claude, Gemini, ChatGPT o Perplexity.
¿Qué es el Content Delivery Network (CDN)?
El Content Delivery Network (CDN, o red de distribución de contenido) es, como dice su nombre, una red de servidores distribuidos en distintas ubicaciones geográficas que guarda contenido en caché (copias temporales de archivos o páginas). Esto permite servir páginas, imágenes, archivos JS (JavaScript) o CSS (hojas de estilo) con menos demora.
Además, reduce solicitudes directas al servidor de origen y puede ayudar con el rendimiento, los costes y cierta protección frente a tráfico malicioso.
El punto que hay que destacar aquí es que muchos bots no llegan primero al servidor de origen, sino a la capa CDN. Si tu sitio está detrás de Cloudflare u otra CDN, el bot normalmente se topa primero con el edge (el servidor más cercano de esa red), donde puede recibir contenido cacheado, ser filtrado por reglas de seguridad o ser desafiado antes de tocar el hosting real.
Eso significa que la CDN no solo acelera la web. También se convierte en una parte crítica del control de crawlers (bots que recorren la web para rastrear contenido).
¿Qué son los logs?
Los logs son el historial técnico de lo que ocurre en tu sitio. Cada request (solicitud) deja un registro con datos como la IP, la ruta solicitada, el user-agent, la fecha y hora (timestamp), la respuesta HTTP (por ejemplo, 200, 403 o 404) y, según la plataforma, señales adicionales, como si la solicitud fue clasificada como bot, si fue bloqueada por el firewall o si se respondió desde caché.
Cloudflare define sus logs como registros detallados con metadatos útiles para debugging (diagnóstico técnico de errores), ajustes de configuración y análisis de tráfico, especialmente cuando se combinan con los logs del servidor de aplicación.
En este contexto, los logs son la forma más clara de responder preguntas como:
• ¿Googlebot pudo entrar?
• ¿OAI-SearchBot recibió un 200 o un 403?
• ¿El WAF lo desafió?
• ¿GPTBot está haciendo demasiadas solicitudes?
• ¿Estamos bloqueando bots legítimos por error?
¿Cómo trabajan juntos WAF, CDN y logs?
El bot llega primero al CDN; luego, el WAF inspecciona la solicitud y, solo si pasa esa revisión, la request llega al servidor de origen o se responde desde caché. Después, todo ese recorrido queda registrado en los logs.
¿Qué significa para un Saas B2B aparecer como fuente en modelos de lenguaje (LLMs)?
En Google, la señal más importante para aparecer como enlace de apoyo en experiencias de búsqueda en IA generativa en esencia es lo mismo que ya influía en SEO.
Para que una página pueda aparecer en AI Overviews o en AI Mode como supporting link (enlace de apoyo o referencia dentro de una respuesta generada por IA), primero debe estar indexada y ser apta para mostrarse en Google Search con snippet (el fragmento de texto que Google enseña en los resultados).
Google indica de forma explícita que no existen requisitos técnicos adicionales ni “optimizaciones especiales” para aparecer en estas funciones de IA. Se aplican las mismas buenas prácticas y requisitos técnicos de Search.
Estas funciones también pueden usar un enfoque de query fan-out (cuando el sistema lanza varias búsquedas relacionadas en paralelo para construir una mejor respuesta). Por eso, mientras genera la respuesta, el modelo puede identificar páginas de apoyo adicionales, y el conjunto de enlaces mostrados puede variar frente a una búsqueda clásica.
Según OpenAI, la lógica funciona más como un sistema de “dos carriles”, con controles separados: uno para aparecer como fuente en funciones de búsqueda dentro del producto, y otro para permitir o impedir el uso del contenido con fines de entrenamiento.
OpenAI indica que utiliza OAI-SearchBot y GPTBot con controles independientes a través de robots.txt. Por ejemplo, un sitio puede permitir OAI-SearchBot para aparecer en resultados de búsqueda, y al mismo tiempo bloquear GPTBot para indicar que su contenido no debe usarse para entrenamiento.
¿Qué cambia esto en la práctica?
Esto cambia el enfoque editorial del artículo. El punto ya no es “permitir o bloquear la IA” en abstracto, sino separar decisiones según el objetivo:
Distribución (ser citado o enlazado): Permitir los bots de búsqueda adecuados.
Protección (evitar uso para entrenamiento): Bloquear bots específicos de entrenamiento y, cuando aplique, señalizarlo con los tokens o mecanismos diseñados para eso.
Explora más: → Revisa nuestro análisis sobre tendencias de marca para SaaS B2B en 2026, donde desglosamos cómo ganar autoridad y relevancia en un mercado dominado por la IA agéntica.
¿Qué es el archivo robots.txt?
El archivo robots.txt es un documento que se coloca en la raíz de tu dominio (por ejemplo, tusitio.com/robots.txt) y que les indica a los crawlers qué partes del sitio pueden visitar y cuáles no. No sirve para posicionarte por sí solo, pero sí permite que Google entre a ciertas URL, lea su contenido y lo evalúe para indexarlo (guardarlo en su base de datos de búsqueda).
¿Por qué importa robots.txt para aparecer en AI Overviews?
Google explica que, para que una página pueda aparecer como supporting link (enlace de apoyo) en AI Overviews o AI Mode, esa página debe estar indexada y, además, ser apta para mostrarse con snippet (el fragmento de texto que aparece en los resultados de búsqueda).
Si bloqueas en robots.txt las páginas que te interesa que Google use como fuente (por ejemplo, páginas de producto, comparativas, casos de uso, documentación o artículos estratégicos), reduces su posibilidad de aparecer como apoyo en esas experiencias de IA generativa dentro de Search.
¿Por qué robots.txt es vital para un SaaS B2B hoy más que nunca?
Para un SaaS B2B, esto es importante porque gran parte de la captación no depende solo de la home, sino también de páginas que responden preguntas concretas del buyer: integraciones, seguridad, ROI (retorno sobre la inversión), migración, pricing, comparativas o soluciones por industria.
Si esas páginas están abiertas al rastreo, bien enlazadas internamente e indexables, Google puede considerarlas tanto para Search como para sus funciones de IA.
Bot / token | Qué hace | Señal típica de control | Recomendación para un SaaS B2B |
Googlebot | Es el crawler de Google Search. Rastrea e indexa tu contenido para que pueda aparecer en los resultados de búsqueda. Además, su acceso influye en la elegibilidad de una página para funciones de IA dentro de Google Search. | Se controla principalmente con robots.txt. Para limitar qué muestra Google en resultados, se usan controles como noindex, nosnippet, data-nosnippet o max-snippet. | Permitirlo en casi todo el sitio, salvo áreas sensibles o páginas que no quieras indexar. Bloquearlo puede sacarte del índice o reducir mucho tu visibilidad. |
AI Overviews / AI Mode (Google Search) | No son un bot separado. Son funciones de Google Search que generan respuestas con IA y muestran enlaces de apoyo (supporting links). Para que una página pueda aparecer ahí, debe estar indexada y ser apta para mostrarse con snippet . Google aclara que no hay requisitos técnicos extra más allá de los fundamentos normales de SEO. | No se controlan con un bot propio. Dependen del acceso de Googlebot y de los controles de presentación de contenido en Search, como nosnippet, data-nosnippet, max-snippet o noindex. | Permitir la indexación de páginas estratégicas. Si tu preocupación es que Google resuma demasiado el contenido, usa preview controls (controles de vista previa) en lugar de bloquear el rastreo. |
Google-Extended | No es un crawler independiente, sino un token de robots.txt. Sirve para indicar si el contenido que Google ya rastrea puede usarse para el entrenamiento de futuras versiones de Gemini y para grounding (uso del contenido como apoyo para responder con más precisión) en ciertos productos de Google. No afecta la inclusión en Google Search ni funciona como señal de ranking. | Se controla en robots.txt con | Si tu prioridad es proteger contenido propio o diferenciado, bloquéalo sin miedo a perder visibilidad en Search. Si quieres permitir uso en ciertos ecosistemas de Gemini, puedes evaluarlo de forma selectiva. |
OAI-SearchBot | Es el bot de OpenAI para Search. Se usa para mostrar sitios web en los resultados de búsqueda de ChatGPT. Si lo bloqueas, tu sitio no aparecerá en respuestas de búsqueda de ChatGPT, aunque todavía podría aparecer como enlace navegacional en algunos casos. OpenAI recomienda permitirlo en robots.txt y también desde sus rangos de IP publicados. | Se controla con robots.txt usando | Permitirlo si quieres visibilidad como fuente o enlace en búsquedas dentro de ChatGPT. No basta con robots.txt: también hay que revisar que el WAF o la CDN no lo estén frenando. |
GPTBot | Es el bot de OpenAI usado para rastrear contenido que podría emplearse en el entrenamiento de modelos fundacionales (modelos base de IA). OpenAI indica que bloquearlo comunica que tu contenido no debe usarse para entrenamiento. | Se controla con robots.txt usando | Para un SaaS B2B con contenido propietario, documentación valiosa o contenido diferencial, lo más prudente suele ser bloquearlo por defecto y abrirlo solo si hay una decisión explícita de negocio. |
ChatGPT-User | Es un user-agent (identificador técnico que se envía en una solicitud web) que OpenAI usa para ciertas acciones iniciadas directamente por usuarios de ChatGPT o de Custom GPTs. No es crawling automático de la web. OpenAI indica que, como estas visitas nacen de una acción del usuario, las reglas de robots.txt pueden no aplicar. | No se gestiona igual que un crawler automático. Para Search y opt-outs automáticos, OpenAI indica usar OAI-SearchBot. Para este tipo de tráfico, el control práctico suele pasar por WAF, autenticación, permisos por endpoint o rate limits. | Trátalo más como tráfico similar al de un navegador que como un bot clásico de indexación. No asumas que robots.txt lo va a detener. |
Acerca de Framer:
¿Dónde se edita el archivo robots.txt en Framer?
En Framer, el archivo robots.txt se genera automáticamente para cada sitio web publicado. Puedes revisarlo agregando /robots.txt al final de tu dominio.
Configuración de meta tags y headers en Framer
Framer sí permite insertar meta tags (etiquetas dentro del HTML que dan instrucciones a buscadores y navegadores) y structured data (datos estructurados que ayudan a los buscadores a entender mejor el contenido). Esto se gestiona desde Project Settings → Custom Code, donde puedes elegir en qué parte del sitio se inserta el código y si aplica a todo el proyecto o solo a páginas específicas.
Si quieres controlar la indexación de una página concreta, Framer recomienda hacerlo con meta robots (instrucciones para buscadores dentro de la página). En Page Settings puedes desactivar “Show page in search engines” y, cuando vuelves a publicar, Framer añade la etiqueta <meta name="robots" content="noindex">. Esto sigue la recomendación de Google: para evitar que una página aparezca en resultados, lo correcto es usar noindex y no bloquear primero la URL en robots.txt.
Sobre los headers HTTP como X-Robots-Tag (instrucciones que se envían desde el servidor, no desde el HTML), Framer documenta la inserción de código en <head> y <body>, pero no documenta un control directo de cabeceras HTTP desde la plataforma.
¿Cómo verificar que el hosting o la CDN no estén bloqueando bots importantes en Framer?
Como Framer no expone un panel propio de WAF para gestionar bots, la verificación suele hacerse de forma operativa. Primero, conviene comprobar que robots.txt responda correctamente y devuelva un código 200 (respuesta exitosa del servidor). Segundo, si tienes una capa externa delante del sitio, como CDN o WAF, conviene hacer pruebas por user-agent (la identificación técnica que usa un bot al hacer una solicitud) y revisar los logs.
Explora más: →Visita nuestro artículo que explica cómo construir y lanzar tu sitio web con Framer. Aprenderás a sacarle provecho a esta herramienta no-code para que tu negocio destaque, ya sea B2B o B2C.
Acerca de Webflow:
Acceso y edición de robots.txt en Webflow
Webflow sí permite crear y editar el archivo robots.txt. Esto se hace desde Site settings → SEO → Indexing, y el archivo se publica en la raíz del dominio. También conviene recordar algo importante: robots.txt es público. Es útil para dar instrucciones a los bots, pero no sirve como mecanismo de seguridad para proteger contenido sensible.
Control nativo de bots de búsqueda y bots de IA de Webflow
Una ventaja de Webflow es que, además de editar robots.txt, también ofrece Traffic control toggles (interruptores dentro de la interfaz para permitir o bloquear grupos de bots conocidos). Estos controles están en Site settings → SEO → Indexing y pueden generar reglas automáticamente para categorías como Search engine crawlers y AI bots. Webflow incluye en esas listas nombres como Googlebot, OAI-SearchBot, GPTBot, ChatGPT-User, ClaudeBot y PerplexityBot.
Custom code para meta tags específicos en Webflow
Webflow permite añadir meta tags (etiquetas dentro del HTML que le dan instrucciones a buscadores y navegadores) tanto a nivel de sitio como a nivel de página. A nivel global, se hace desde Site settings → Custom code. A nivel individual, se hace desde Page settings → Inside <head> tag. Esto es útil cuando quieres seguir indexando una página, pero controlar cómo se muestra en Google.
Reglas en WAF/CDN y límites de Webflow-hosted
Si tu sitio en Webflow está detrás de un WAF o un CDN externo, hay un riesgo de que termine bloqueando bots legítimos. Cloudflare, por ejemplo, documenta reglas para permitir verified bots (bots verificados) usando el campo cf.client.bot, precisamente para evitar ese problema.
Sobre los headers HTTP (cabeceras técnicas que envía el servidor), Webflow sí ofrece custom security headers, pero esa función es solo para clientes Enterprise y está limitada a un conjunto concreto de headers, como x-frame-options, content-security-policy o strict-transport-security.
Acerca de WordPress:
Plugins recomendados para gestionar robots.txt en WordPress
En WordPress puedes encontrarte con dos tipos de archivo robots.txt:
Virtual: Lo genera WordPress automáticamente, aunque no exista un archivo físico en el servidor.
Físico: Es un archivo real que está guardado en la raíz del sitio (la carpeta principal del dominio).
La Yoast explica ambos escenarios. WordPress genera un robots.txt por defecto y, si creas uno desde Yoast, el plugin reemplaza esa versión por defecto y añade su propia configuración, incluida la referencia al sitemap (el archivo que ayuda a los buscadores a descubrir las páginas del sitio).
Además, Yoast incluye un File Editor dentro del panel de administración (Yoast SEO → Tools → File Editor) para editar robots.txt y, según el servidor, también .htaccess (un archivo de configuración usado en servidores Apache para definir reglas del sitio).
Plugins de seguridad o WAF en WordPress y cómo verificar que no bloquean bots de búsqueda
En WordPress es bastante común que un plugin de seguridad o un WAF termine limitando o bloqueando crawlers sin querer.
Wordfence documenta su sistema de Rate Limiting (una función que limita cuántas solicitudes puede hacer una misma fuente en un periodo de tiempo) y aclara que puedes decidir cómo tratar a los crawlers de Google, incluso dando acceso ilimitado solo a bots verificados mediante reverse DNS (PTR) (una comprobación técnica para validar que una IP realmente pertenece a Google).
Explora más: → Visita nuestro artículo sobre Framer vs WordPress para SaaS B2B. Aprenderás qué plataforma se adapta mejor a tu negocio según velocidad de ejecución, performance, marketing y capacidad de crecimiento.
Checklist de validación y monitoreo
Para founders y equipos de marketing de SaaS B2B, el estándar debería ser este: probar y observar antes de asumir que una configuración está funcionando bien.
Estos son algunos checks básicos para validar si un sitio alojado en Framer, Webflow, WordPress u otra infraestructura está bien preparado para aparecer en AI Overviews o en búsquedas dentro de agentes de IA generativa.
Validar cómo ve Google tu página
Google recomienda usar la herramienta URL Inspection (una función de Google Search Console que muestra cómo Googlebot ve una página) para revisar el HTML que recibió al rastrear la URL. Esto sirve para comprobar si los preview controls (controles que limitan o ajustan lo que Google puede mostrar, como snippets o previews) están visibles y configurados correctamente.

Validar el “carril OpenAI”
En el caso de OpenAI, la documentación indica que los cambios en robots.txt pueden tardar alrededor de 24 horas en reflejarse en sus sistemas de Search.
Además, si tu stack usa un WAF o una CDN, OpenAI recomienda permitir OAI-SearchBot en robots.txt y también permitir solicitudes desde sus rangos de IP publicados. Esto aumenta la probabilidad de que tu sitio pueda aparecer en resultados de búsqueda dentro de sus productos.
¿Cómo bloquear secciones de tu web?
Tu decisión puede resumirse así:
¿Quieres aparecer como fuente o enlace en experiencias con IA?
Sí → Mantén la indexación en Google y permite OAI-SearchBot.
No → Bloquea el crawling relevante. Ten en cuenta que eso puede sacarte del índice de Google y también excluirte de ciertos resultados en buscadores con IA.
¿Quieres evitar entrenamiento o grounding por parte de proveedores de IA?
Sí → Bloquea GPTBot y Google-Extended, sin tocar Googlebot.
No, o solo en algunos casos → Permite el acceso por rutas o según tu política editorial (por ejemplo, permitir el blog, pero bloquear documentación premium), y controla cuánto puede mostrarse con preview controls cuando haga falta.
¿Cómo Noodlesoup puede ayudarte?
Para un founder de SaaS B2B, el sitio web es una pieza central de autoridad y crecimiento. Es el lugar donde tu propuesta de valor se vuelve creíble para tus clientes potenciales y, ahora, también para los nuevos sistemas de descubrimiento impulsados por la IA generativa.
En Noodlesoup ayudamos a equipos que sienten que su sitio actual ya no refleja la calidad de su producto o no les da la agilidad que necesitan para evolucionar. En esos casos, podemos acompañarte a migrar tu web desde plataformas como WordPress o Webflow hacia Framer, construyendo una base más clara y más fácil de operar para marketing y negocio.
Y, si quieres crear un sitio web desde cero, también podemos diseñarlo y desarrollarlo en Framer, teniendo en cuenta una arquitectura clara, páginas estratégicas bien definidas, contenido que responde preguntas reales del buyer y una configuración técnica que favorezca la visibilidad en Google Search, AI Overviews y entornos de búsqueda dentro de asistentes y agentes de IA.
FAQs:
¿Qué pasa si no configuro nada y dejo los bots de IA como están?
Tu sitio puede seguir apareciendo en Google si cumple los fundamentos normales de SEO, pero también puedes estar permitiendo o bloqueando cosas sin darte cuenta. En OpenAI, además, la visibilidad en ChatGPT Search y el uso del contenido para entrenamiento se controlan por separado, así que conviene definir esa política de forma explícita.
¿Cómo decido qué partes de mi web abrir y cuáles proteger?
Abre las páginas que te ayudan a ser descubierto, como producto, comparativas, casos de uso o blog. Protege las partes más sensibles o diferenciales, como documentación privada, contenido premium o recursos internos. Google permite limitar cómo se muestra el contenido sin tener que cerrar toda la página, y OpenAI permite dejar visible tu sitio en ChatGPT Search sin autorizar entrenamiento.
¿Cómo sé si aparecer en Google o AI Overviews me está trayendo oportunidades?
Google incluye estas apariciones dentro del rendimiento general en Search Console, y recomienda unirlo con Analytics para ver qué visitas generan tiempo en sitio, formularios o demos.
¿Por qué actualmente es valioso para un SaaS B2B?
Los sistemas de búsqueda con IA por ejemplo: experiencias como AI Overviews o búsquedas dentro de asistentes de IA generativa (herramientas que crean respuestas en lenguaje natural a partir de múltiples fuentes) ya están seleccionando y mostrando enlaces a sitios web.
En la documentación de AI features de Google Search, explica que las IA Overviews muestran enlaces relevantes para ayudar al usuario a explorar mejor un tema, y que esto puede convertirse en un canal real de descubrimiento de marca y de tráfico cualificado para los Saas B2B.
Google también afirma haber observado que, cuando los usuarios hacen clic en resultados con AI Overviews, esos clics suelen ser de mayor calidad, por ejemplo, con más tiempo de permanencia en el sitio. Según Cloudflare, el tráfico conjunto de crawlers de búsqueda e IA creció un 18 % entre mayo de 2024 y mayo de 2025.
¿Qué es el Web Application Firewall (WAF)?
El Web Application Firewall (WAF, o firewall de aplicaciones web) es una capa de protección que se pone en tu sitio web para filtrar y monitorear el tráfico HTTP (las solicitudes que llegan a una web) antes de que alcance tu aplicación.
Su función es permitir, bloquear, desafiar o aplicar rate limiting (limitar cuántas solicitudes puede hacer una misma fuente en un periodo de tiempo) según factores como la IP, el país, patrones de ataque, el user-agent (la identificación que un navegador o bot envía al hacer una solicitud) o señales de comportamiento automatizado.
El WAF es una de las capas que más fácilmente puede romper una estrategia de visibilidad para los motores de IA generativa. Puedes haber permitido un bot en robots.txt (explicaremos el concepto más adelante), pero, si el WAF lo desafía o lo bloquea con una regla anti-bot, ese crawler igual no va a entrar.
Por eso, lo recomendable es no solo permitir OAI-SearchBot en robots.txt, sino también autorizar solicitudes desde los rangos de IP publicados, si quieres aparecer en resultados de búsqueda dentro de Claude, Gemini, ChatGPT o Perplexity.
¿Qué es el Content Delivery Network (CDN)?
El Content Delivery Network (CDN, o red de distribución de contenido) es, como dice su nombre, una red de servidores distribuidos en distintas ubicaciones geográficas que guarda contenido en caché (copias temporales de archivos o páginas). Esto permite servir páginas, imágenes, archivos JS (JavaScript) o CSS (hojas de estilo) con menos demora.
Además, reduce solicitudes directas al servidor de origen y puede ayudar con el rendimiento, los costes y cierta protección frente a tráfico malicioso.
El punto que hay que destacar aquí es que muchos bots no llegan primero al servidor de origen, sino a la capa CDN. Si tu sitio está detrás de Cloudflare u otra CDN, el bot normalmente se topa primero con el edge (el servidor más cercano de esa red), donde puede recibir contenido cacheado, ser filtrado por reglas de seguridad o ser desafiado antes de tocar el hosting real.
Eso significa que la CDN no solo acelera la web. También se convierte en una parte crítica del control de crawlers (bots que recorren la web para rastrear contenido).
¿Qué son los logs?
Los logs son el historial técnico de lo que ocurre en tu sitio. Cada request (solicitud) deja un registro con datos como la IP, la ruta solicitada, el user-agent, la fecha y hora (timestamp), la respuesta HTTP (por ejemplo, 200, 403 o 404) y, según la plataforma, señales adicionales, como si la solicitud fue clasificada como bot, si fue bloqueada por el firewall o si se respondió desde caché.
Cloudflare define sus logs como registros detallados con metadatos útiles para debugging (diagnóstico técnico de errores), ajustes de configuración y análisis de tráfico, especialmente cuando se combinan con los logs del servidor de aplicación.
En este contexto, los logs son la forma más clara de responder preguntas como:
• ¿Googlebot pudo entrar?
• ¿OAI-SearchBot recibió un 200 o un 403?
• ¿El WAF lo desafió?
• ¿GPTBot está haciendo demasiadas solicitudes?
• ¿Estamos bloqueando bots legítimos por error?
¿Cómo trabajan juntos WAF, CDN y logs?
El bot llega primero al CDN; luego, el WAF inspecciona la solicitud y, solo si pasa esa revisión, la request llega al servidor de origen o se responde desde caché. Después, todo ese recorrido queda registrado en los logs.
¿Qué significa para un Saas B2B aparecer como fuente en modelos de lenguaje (LLMs)?
En Google, la señal más importante para aparecer como enlace de apoyo en experiencias de búsqueda en IA generativa en esencia es lo mismo que ya influía en SEO.
Para que una página pueda aparecer en AI Overviews o en AI Mode como supporting link (enlace de apoyo o referencia dentro de una respuesta generada por IA), primero debe estar indexada y ser apta para mostrarse en Google Search con snippet (el fragmento de texto que Google enseña en los resultados).
Google indica de forma explícita que no existen requisitos técnicos adicionales ni “optimizaciones especiales” para aparecer en estas funciones de IA. Se aplican las mismas buenas prácticas y requisitos técnicos de Search.
Estas funciones también pueden usar un enfoque de query fan-out (cuando el sistema lanza varias búsquedas relacionadas en paralelo para construir una mejor respuesta). Por eso, mientras genera la respuesta, el modelo puede identificar páginas de apoyo adicionales, y el conjunto de enlaces mostrados puede variar frente a una búsqueda clásica.
Según OpenAI, la lógica funciona más como un sistema de “dos carriles”, con controles separados: uno para aparecer como fuente en funciones de búsqueda dentro del producto, y otro para permitir o impedir el uso del contenido con fines de entrenamiento.
OpenAI indica que utiliza OAI-SearchBot y GPTBot con controles independientes a través de robots.txt. Por ejemplo, un sitio puede permitir OAI-SearchBot para aparecer en resultados de búsqueda, y al mismo tiempo bloquear GPTBot para indicar que su contenido no debe usarse para entrenamiento.
¿Qué cambia esto en la práctica?
Esto cambia el enfoque editorial del artículo. El punto ya no es “permitir o bloquear la IA” en abstracto, sino separar decisiones según el objetivo:
Distribución (ser citado o enlazado): Permitir los bots de búsqueda adecuados.
Protección (evitar uso para entrenamiento): Bloquear bots específicos de entrenamiento y, cuando aplique, señalizarlo con los tokens o mecanismos diseñados para eso.
Explora más: → Revisa nuestro análisis sobre tendencias de marca para SaaS B2B en 2026, donde desglosamos cómo ganar autoridad y relevancia en un mercado dominado por la IA agéntica.
¿Qué es el archivo robots.txt?
El archivo robots.txt es un documento que se coloca en la raíz de tu dominio (por ejemplo, tusitio.com/robots.txt) y que les indica a los crawlers qué partes del sitio pueden visitar y cuáles no. No sirve para posicionarte por sí solo, pero sí permite que Google entre a ciertas URL, lea su contenido y lo evalúe para indexarlo (guardarlo en su base de datos de búsqueda).
¿Por qué importa robots.txt para aparecer en AI Overviews?
Google explica que, para que una página pueda aparecer como supporting link (enlace de apoyo) en AI Overviews o AI Mode, esa página debe estar indexada y, además, ser apta para mostrarse con snippet (el fragmento de texto que aparece en los resultados de búsqueda).
Si bloqueas en robots.txt las páginas que te interesa que Google use como fuente (por ejemplo, páginas de producto, comparativas, casos de uso, documentación o artículos estratégicos), reduces su posibilidad de aparecer como apoyo en esas experiencias de IA generativa dentro de Search.
¿Por qué robots.txt es vital para un SaaS B2B hoy más que nunca?
Para un SaaS B2B, esto es importante porque gran parte de la captación no depende solo de la home, sino también de páginas que responden preguntas concretas del buyer: integraciones, seguridad, ROI (retorno sobre la inversión), migración, pricing, comparativas o soluciones por industria.
Si esas páginas están abiertas al rastreo, bien enlazadas internamente e indexables, Google puede considerarlas tanto para Search como para sus funciones de IA.
Bot / token | Qué hace | Señal típica de control | Recomendación para un SaaS B2B |
Googlebot | Es el crawler de Google Search. Rastrea e indexa tu contenido para que pueda aparecer en los resultados de búsqueda. Además, su acceso influye en la elegibilidad de una página para funciones de IA dentro de Google Search. | Se controla principalmente con robots.txt. Para limitar qué muestra Google en resultados, se usan controles como noindex, nosnippet, data-nosnippet o max-snippet. | Permitirlo en casi todo el sitio, salvo áreas sensibles o páginas que no quieras indexar. Bloquearlo puede sacarte del índice o reducir mucho tu visibilidad. |
AI Overviews / AI Mode (Google Search) | No son un bot separado. Son funciones de Google Search que generan respuestas con IA y muestran enlaces de apoyo (supporting links). Para que una página pueda aparecer ahí, debe estar indexada y ser apta para mostrarse con snippet . Google aclara que no hay requisitos técnicos extra más allá de los fundamentos normales de SEO. | No se controlan con un bot propio. Dependen del acceso de Googlebot y de los controles de presentación de contenido en Search, como nosnippet, data-nosnippet, max-snippet o noindex. | Permitir la indexación de páginas estratégicas. Si tu preocupación es que Google resuma demasiado el contenido, usa preview controls (controles de vista previa) en lugar de bloquear el rastreo. |
Google-Extended | No es un crawler independiente, sino un token de robots.txt. Sirve para indicar si el contenido que Google ya rastrea puede usarse para el entrenamiento de futuras versiones de Gemini y para grounding (uso del contenido como apoyo para responder con más precisión) en ciertos productos de Google. No afecta la inclusión en Google Search ni funciona como señal de ranking. | Se controla en robots.txt con | Si tu prioridad es proteger contenido propio o diferenciado, bloquéalo sin miedo a perder visibilidad en Search. Si quieres permitir uso en ciertos ecosistemas de Gemini, puedes evaluarlo de forma selectiva. |
OAI-SearchBot | Es el bot de OpenAI para Search. Se usa para mostrar sitios web en los resultados de búsqueda de ChatGPT. Si lo bloqueas, tu sitio no aparecerá en respuestas de búsqueda de ChatGPT, aunque todavía podría aparecer como enlace navegacional en algunos casos. OpenAI recomienda permitirlo en robots.txt y también desde sus rangos de IP publicados. | Se controla con robots.txt usando | Permitirlo si quieres visibilidad como fuente o enlace en búsquedas dentro de ChatGPT. No basta con robots.txt: también hay que revisar que el WAF o la CDN no lo estén frenando. |
GPTBot | Es el bot de OpenAI usado para rastrear contenido que podría emplearse en el entrenamiento de modelos fundacionales (modelos base de IA). OpenAI indica que bloquearlo comunica que tu contenido no debe usarse para entrenamiento. | Se controla con robots.txt usando | Para un SaaS B2B con contenido propietario, documentación valiosa o contenido diferencial, lo más prudente suele ser bloquearlo por defecto y abrirlo solo si hay una decisión explícita de negocio. |
ChatGPT-User | Es un user-agent (identificador técnico que se envía en una solicitud web) que OpenAI usa para ciertas acciones iniciadas directamente por usuarios de ChatGPT o de Custom GPTs. No es crawling automático de la web. OpenAI indica que, como estas visitas nacen de una acción del usuario, las reglas de robots.txt pueden no aplicar. | No se gestiona igual que un crawler automático. Para Search y opt-outs automáticos, OpenAI indica usar OAI-SearchBot. Para este tipo de tráfico, el control práctico suele pasar por WAF, autenticación, permisos por endpoint o rate limits. | Trátalo más como tráfico similar al de un navegador que como un bot clásico de indexación. No asumas que robots.txt lo va a detener. |
Acerca de Framer:
¿Dónde se edita el archivo robots.txt en Framer?
En Framer, el archivo robots.txt se genera automáticamente para cada sitio web publicado. Puedes revisarlo agregando /robots.txt al final de tu dominio.
Configuración de meta tags y headers en Framer
Framer sí permite insertar meta tags (etiquetas dentro del HTML que dan instrucciones a buscadores y navegadores) y structured data (datos estructurados que ayudan a los buscadores a entender mejor el contenido). Esto se gestiona desde Project Settings → Custom Code, donde puedes elegir en qué parte del sitio se inserta el código y si aplica a todo el proyecto o solo a páginas específicas.
Si quieres controlar la indexación de una página concreta, Framer recomienda hacerlo con meta robots (instrucciones para buscadores dentro de la página). En Page Settings puedes desactivar “Show page in search engines” y, cuando vuelves a publicar, Framer añade la etiqueta <meta name="robots" content="noindex">. Esto sigue la recomendación de Google: para evitar que una página aparezca en resultados, lo correcto es usar noindex y no bloquear primero la URL en robots.txt.
Sobre los headers HTTP como X-Robots-Tag (instrucciones que se envían desde el servidor, no desde el HTML), Framer documenta la inserción de código en <head> y <body>, pero no documenta un control directo de cabeceras HTTP desde la plataforma.
¿Cómo verificar que el hosting o la CDN no estén bloqueando bots importantes en Framer?
Como Framer no expone un panel propio de WAF para gestionar bots, la verificación suele hacerse de forma operativa. Primero, conviene comprobar que robots.txt responda correctamente y devuelva un código 200 (respuesta exitosa del servidor). Segundo, si tienes una capa externa delante del sitio, como CDN o WAF, conviene hacer pruebas por user-agent (la identificación técnica que usa un bot al hacer una solicitud) y revisar los logs.
Explora más: →Visita nuestro artículo que explica cómo construir y lanzar tu sitio web con Framer. Aprenderás a sacarle provecho a esta herramienta no-code para que tu negocio destaque, ya sea B2B o B2C.
Acerca de Webflow:
Acceso y edición de robots.txt en Webflow
Webflow sí permite crear y editar el archivo robots.txt. Esto se hace desde Site settings → SEO → Indexing, y el archivo se publica en la raíz del dominio. También conviene recordar algo importante: robots.txt es público. Es útil para dar instrucciones a los bots, pero no sirve como mecanismo de seguridad para proteger contenido sensible.
Control nativo de bots de búsqueda y bots de IA de Webflow
Una ventaja de Webflow es que, además de editar robots.txt, también ofrece Traffic control toggles (interruptores dentro de la interfaz para permitir o bloquear grupos de bots conocidos). Estos controles están en Site settings → SEO → Indexing y pueden generar reglas automáticamente para categorías como Search engine crawlers y AI bots. Webflow incluye en esas listas nombres como Googlebot, OAI-SearchBot, GPTBot, ChatGPT-User, ClaudeBot y PerplexityBot.
Custom code para meta tags específicos en Webflow
Webflow permite añadir meta tags (etiquetas dentro del HTML que le dan instrucciones a buscadores y navegadores) tanto a nivel de sitio como a nivel de página. A nivel global, se hace desde Site settings → Custom code. A nivel individual, se hace desde Page settings → Inside <head> tag. Esto es útil cuando quieres seguir indexando una página, pero controlar cómo se muestra en Google.
Reglas en WAF/CDN y límites de Webflow-hosted
Si tu sitio en Webflow está detrás de un WAF o un CDN externo, hay un riesgo de que termine bloqueando bots legítimos. Cloudflare, por ejemplo, documenta reglas para permitir verified bots (bots verificados) usando el campo cf.client.bot, precisamente para evitar ese problema.
Sobre los headers HTTP (cabeceras técnicas que envía el servidor), Webflow sí ofrece custom security headers, pero esa función es solo para clientes Enterprise y está limitada a un conjunto concreto de headers, como x-frame-options, content-security-policy o strict-transport-security.
Acerca de WordPress:
Plugins recomendados para gestionar robots.txt en WordPress
En WordPress puedes encontrarte con dos tipos de archivo robots.txt:
Virtual: Lo genera WordPress automáticamente, aunque no exista un archivo físico en el servidor.
Físico: Es un archivo real que está guardado en la raíz del sitio (la carpeta principal del dominio).
La Yoast explica ambos escenarios. WordPress genera un robots.txt por defecto y, si creas uno desde Yoast, el plugin reemplaza esa versión por defecto y añade su propia configuración, incluida la referencia al sitemap (el archivo que ayuda a los buscadores a descubrir las páginas del sitio).
Además, Yoast incluye un File Editor dentro del panel de administración (Yoast SEO → Tools → File Editor) para editar robots.txt y, según el servidor, también .htaccess (un archivo de configuración usado en servidores Apache para definir reglas del sitio).
Plugins de seguridad o WAF en WordPress y cómo verificar que no bloquean bots de búsqueda
En WordPress es bastante común que un plugin de seguridad o un WAF termine limitando o bloqueando crawlers sin querer.
Wordfence documenta su sistema de Rate Limiting (una función que limita cuántas solicitudes puede hacer una misma fuente en un periodo de tiempo) y aclara que puedes decidir cómo tratar a los crawlers de Google, incluso dando acceso ilimitado solo a bots verificados mediante reverse DNS (PTR) (una comprobación técnica para validar que una IP realmente pertenece a Google).
Explora más: → Visita nuestro artículo sobre Framer vs WordPress para SaaS B2B. Aprenderás qué plataforma se adapta mejor a tu negocio según velocidad de ejecución, performance, marketing y capacidad de crecimiento.
Checklist de validación y monitoreo
Para founders y equipos de marketing de SaaS B2B, el estándar debería ser este: probar y observar antes de asumir que una configuración está funcionando bien.
Estos son algunos checks básicos para validar si un sitio alojado en Framer, Webflow, WordPress u otra infraestructura está bien preparado para aparecer en AI Overviews o en búsquedas dentro de agentes de IA generativa.
Validar cómo ve Google tu página
Google recomienda usar la herramienta URL Inspection (una función de Google Search Console que muestra cómo Googlebot ve una página) para revisar el HTML que recibió al rastrear la URL. Esto sirve para comprobar si los preview controls (controles que limitan o ajustan lo que Google puede mostrar, como snippets o previews) están visibles y configurados correctamente.
Validar el “carril OpenAI”
En el caso de OpenAI, la documentación indica que los cambios en robots.txt pueden tardar alrededor de 24 horas en reflejarse en sus sistemas de Search.
Además, si tu stack usa un WAF o una CDN, OpenAI recomienda permitir OAI-SearchBot en robots.txt y también permitir solicitudes desde sus rangos de IP publicados. Esto aumenta la probabilidad de que tu sitio pueda aparecer en resultados de búsqueda dentro de sus productos.
¿Cómo bloquear secciones de tu web?
Tu decisión puede resumirse así:
¿Quieres aparecer como fuente o enlace en experiencias con IA?
Sí → Mantén la indexación en Google y permite OAI-SearchBot.
No → Bloquea el crawling relevante. Ten en cuenta que eso puede sacarte del índice de Google y también excluirte de ciertos resultados en buscadores con IA.
¿Quieres evitar entrenamiento o grounding por parte de proveedores de IA?
Sí → Bloquea GPTBot y Google-Extended, sin tocar Googlebot.
No, o solo en algunos casos → Permite el acceso por rutas o según tu política editorial (por ejemplo, permitir el blog, pero bloquear documentación premium), y controla cuánto puede mostrarse con preview controls cuando haga falta.
¿Cómo Noodlesoup puede ayudarte?
Para un founder de SaaS B2B, el sitio web es una pieza central de autoridad y crecimiento. Es el lugar donde tu propuesta de valor se vuelve creíble para tus clientes potenciales y, ahora, también para los nuevos sistemas de descubrimiento impulsados por la IA generativa.
En Noodlesoup ayudamos a equipos que sienten que su sitio actual ya no refleja la calidad de su producto o no les da la agilidad que necesitan para evolucionar. En esos casos, podemos acompañarte a migrar tu web desde plataformas como WordPress o Webflow hacia Framer, construyendo una base más clara y más fácil de operar para marketing y negocio.
Y, si quieres crear un sitio web desde cero, también podemos diseñarlo y desarrollarlo en Framer, teniendo en cuenta una arquitectura clara, páginas estratégicas bien definidas, contenido que responde preguntas reales del buyer y una configuración técnica que favorezca la visibilidad en Google Search, AI Overviews y entornos de búsqueda dentro de asistentes y agentes de IA.
FAQs:
¿Qué pasa si no configuro nada y dejo los bots de IA como están?
Tu sitio puede seguir apareciendo en Google si cumple los fundamentos normales de SEO, pero también puedes estar permitiendo o bloqueando cosas sin darte cuenta. En OpenAI, además, la visibilidad en ChatGPT Search y el uso del contenido para entrenamiento se controlan por separado, así que conviene definir esa política de forma explícita.
¿Cómo decido qué partes de mi web abrir y cuáles proteger?
Abre las páginas que te ayudan a ser descubierto, como producto, comparativas, casos de uso o blog. Protege las partes más sensibles o diferenciales, como documentación privada, contenido premium o recursos internos. Google permite limitar cómo se muestra el contenido sin tener que cerrar toda la página, y OpenAI permite dejar visible tu sitio en ChatGPT Search sin autorizar entrenamiento.
¿Cómo sé si aparecer en Google o AI Overviews me está trayendo oportunidades?
Google incluye estas apariciones dentro del rendimiento general en Search Console, y recomienda unirlo con Analytics para ver qué visitas generan tiempo en sitio, formularios o demos.
¿Por qué actualmente es valioso para un SaaS B2B?
Los sistemas de búsqueda con IA por ejemplo: experiencias como AI Overviews o búsquedas dentro de asistentes de IA generativa (herramientas que crean respuestas en lenguaje natural a partir de múltiples fuentes) ya están seleccionando y mostrando enlaces a sitios web.
En la documentación de AI features de Google Search, explica que las IA Overviews muestran enlaces relevantes para ayudar al usuario a explorar mejor un tema, y que esto puede convertirse en un canal real de descubrimiento de marca y de tráfico cualificado para los Saas B2B.
Google también afirma haber observado que, cuando los usuarios hacen clic en resultados con AI Overviews, esos clics suelen ser de mayor calidad, por ejemplo, con más tiempo de permanencia en el sitio. Según Cloudflare, el tráfico conjunto de crawlers de búsqueda e IA creció un 18 % entre mayo de 2024 y mayo de 2025.
¿Qué es el Web Application Firewall (WAF)?
El Web Application Firewall (WAF, o firewall de aplicaciones web) es una capa de protección que se pone en tu sitio web para filtrar y monitorear el tráfico HTTP (las solicitudes que llegan a una web) antes de que alcance tu aplicación.
Su función es permitir, bloquear, desafiar o aplicar rate limiting (limitar cuántas solicitudes puede hacer una misma fuente en un periodo de tiempo) según factores como la IP, el país, patrones de ataque, el user-agent (la identificación que un navegador o bot envía al hacer una solicitud) o señales de comportamiento automatizado.
El WAF es una de las capas que más fácilmente puede romper una estrategia de visibilidad para los motores de IA generativa. Puedes haber permitido un bot en robots.txt (explicaremos el concepto más adelante), pero, si el WAF lo desafía o lo bloquea con una regla anti-bot, ese crawler igual no va a entrar.
Por eso, lo recomendable es no solo permitir OAI-SearchBot en robots.txt, sino también autorizar solicitudes desde los rangos de IP publicados, si quieres aparecer en resultados de búsqueda dentro de Claude, Gemini, ChatGPT o Perplexity.
¿Qué es el Content Delivery Network (CDN)?
El Content Delivery Network (CDN, o red de distribución de contenido) es, como dice su nombre, una red de servidores distribuidos en distintas ubicaciones geográficas que guarda contenido en caché (copias temporales de archivos o páginas). Esto permite servir páginas, imágenes, archivos JS (JavaScript) o CSS (hojas de estilo) con menos demora.
Además, reduce solicitudes directas al servidor de origen y puede ayudar con el rendimiento, los costes y cierta protección frente a tráfico malicioso.
El punto que hay que destacar aquí es que muchos bots no llegan primero al servidor de origen, sino a la capa CDN. Si tu sitio está detrás de Cloudflare u otra CDN, el bot normalmente se topa primero con el edge (el servidor más cercano de esa red), donde puede recibir contenido cacheado, ser filtrado por reglas de seguridad o ser desafiado antes de tocar el hosting real.
Eso significa que la CDN no solo acelera la web. También se convierte en una parte crítica del control de crawlers (bots que recorren la web para rastrear contenido).
¿Qué son los logs?
Los logs son el historial técnico de lo que ocurre en tu sitio. Cada request (solicitud) deja un registro con datos como la IP, la ruta solicitada, el user-agent, la fecha y hora (timestamp), la respuesta HTTP (por ejemplo, 200, 403 o 404) y, según la plataforma, señales adicionales, como si la solicitud fue clasificada como bot, si fue bloqueada por el firewall o si se respondió desde caché.
Cloudflare define sus logs como registros detallados con metadatos útiles para debugging (diagnóstico técnico de errores), ajustes de configuración y análisis de tráfico, especialmente cuando se combinan con los logs del servidor de aplicación.
En este contexto, los logs son la forma más clara de responder preguntas como:
• ¿Googlebot pudo entrar?
• ¿OAI-SearchBot recibió un 200 o un 403?
• ¿El WAF lo desafió?
• ¿GPTBot está haciendo demasiadas solicitudes?
• ¿Estamos bloqueando bots legítimos por error?
¿Cómo trabajan juntos WAF, CDN y logs?
El bot llega primero al CDN; luego, el WAF inspecciona la solicitud y, solo si pasa esa revisión, la request llega al servidor de origen o se responde desde caché. Después, todo ese recorrido queda registrado en los logs.
¿Qué significa para un Saas B2B aparecer como fuente en modelos de lenguaje (LLMs)?
En Google, la señal más importante para aparecer como enlace de apoyo en experiencias de búsqueda en IA generativa en esencia es lo mismo que ya influía en SEO.
Para que una página pueda aparecer en AI Overviews o en AI Mode como supporting link (enlace de apoyo o referencia dentro de una respuesta generada por IA), primero debe estar indexada y ser apta para mostrarse en Google Search con snippet (el fragmento de texto que Google enseña en los resultados).
Google indica de forma explícita que no existen requisitos técnicos adicionales ni “optimizaciones especiales” para aparecer en estas funciones de IA. Se aplican las mismas buenas prácticas y requisitos técnicos de Search.
Estas funciones también pueden usar un enfoque de query fan-out (cuando el sistema lanza varias búsquedas relacionadas en paralelo para construir una mejor respuesta). Por eso, mientras genera la respuesta, el modelo puede identificar páginas de apoyo adicionales, y el conjunto de enlaces mostrados puede variar frente a una búsqueda clásica.
Según OpenAI, la lógica funciona más como un sistema de “dos carriles”, con controles separados: uno para aparecer como fuente en funciones de búsqueda dentro del producto, y otro para permitir o impedir el uso del contenido con fines de entrenamiento.
OpenAI indica que utiliza OAI-SearchBot y GPTBot con controles independientes a través de robots.txt. Por ejemplo, un sitio puede permitir OAI-SearchBot para aparecer en resultados de búsqueda, y al mismo tiempo bloquear GPTBot para indicar que su contenido no debe usarse para entrenamiento.
¿Qué cambia esto en la práctica?
Esto cambia el enfoque editorial del artículo. El punto ya no es “permitir o bloquear la IA” en abstracto, sino separar decisiones según el objetivo:
Distribución (ser citado o enlazado): Permitir los bots de búsqueda adecuados.
Protección (evitar uso para entrenamiento): Bloquear bots específicos de entrenamiento y, cuando aplique, señalizarlo con los tokens o mecanismos diseñados para eso.
Explora más: → Revisa nuestro análisis sobre tendencias de marca para SaaS B2B en 2026, donde desglosamos cómo ganar autoridad y relevancia en un mercado dominado por la IA agéntica.
¿Qué es el archivo robots.txt?
El archivo robots.txt es un documento que se coloca en la raíz de tu dominio (por ejemplo, tusitio.com/robots.txt) y que les indica a los crawlers qué partes del sitio pueden visitar y cuáles no. No sirve para posicionarte por sí solo, pero sí permite que Google entre a ciertas URL, lea su contenido y lo evalúe para indexarlo (guardarlo en su base de datos de búsqueda).
¿Por qué importa robots.txt para aparecer en AI Overviews?
Google explica que, para que una página pueda aparecer como supporting link (enlace de apoyo) en AI Overviews o AI Mode, esa página debe estar indexada y, además, ser apta para mostrarse con snippet (el fragmento de texto que aparece en los resultados de búsqueda).
Si bloqueas en robots.txt las páginas que te interesa que Google use como fuente (por ejemplo, páginas de producto, comparativas, casos de uso, documentación o artículos estratégicos), reduces su posibilidad de aparecer como apoyo en esas experiencias de IA generativa dentro de Search.
¿Por qué robots.txt es vital para un SaaS B2B hoy más que nunca?
Para un SaaS B2B, esto es importante porque gran parte de la captación no depende solo de la home, sino también de páginas que responden preguntas concretas del buyer: integraciones, seguridad, ROI (retorno sobre la inversión), migración, pricing, comparativas o soluciones por industria.
Si esas páginas están abiertas al rastreo, bien enlazadas internamente e indexables, Google puede considerarlas tanto para Search como para sus funciones de IA.
Bot / token | Qué hace | Señal típica de control | Recomendación para un SaaS B2B |
Googlebot | Es el crawler de Google Search. Rastrea e indexa tu contenido para que pueda aparecer en los resultados de búsqueda. Además, su acceso influye en la elegibilidad de una página para funciones de IA dentro de Google Search. | Se controla principalmente con robots.txt. Para limitar qué muestra Google en resultados, se usan controles como noindex, nosnippet, data-nosnippet o max-snippet. | Permitirlo en casi todo el sitio, salvo áreas sensibles o páginas que no quieras indexar. Bloquearlo puede sacarte del índice o reducir mucho tu visibilidad. |
AI Overviews / AI Mode (Google Search) | No son un bot separado. Son funciones de Google Search que generan respuestas con IA y muestran enlaces de apoyo (supporting links). Para que una página pueda aparecer ahí, debe estar indexada y ser apta para mostrarse con snippet . Google aclara que no hay requisitos técnicos extra más allá de los fundamentos normales de SEO. | No se controlan con un bot propio. Dependen del acceso de Googlebot y de los controles de presentación de contenido en Search, como nosnippet, data-nosnippet, max-snippet o noindex. | Permitir la indexación de páginas estratégicas. Si tu preocupación es que Google resuma demasiado el contenido, usa preview controls (controles de vista previa) en lugar de bloquear el rastreo. |
Google-Extended | No es un crawler independiente, sino un token de robots.txt. Sirve para indicar si el contenido que Google ya rastrea puede usarse para el entrenamiento de futuras versiones de Gemini y para grounding (uso del contenido como apoyo para responder con más precisión) en ciertos productos de Google. No afecta la inclusión en Google Search ni funciona como señal de ranking. | Se controla en robots.txt con | Si tu prioridad es proteger contenido propio o diferenciado, bloquéalo sin miedo a perder visibilidad en Search. Si quieres permitir uso en ciertos ecosistemas de Gemini, puedes evaluarlo de forma selectiva. |
OAI-SearchBot | Es el bot de OpenAI para Search. Se usa para mostrar sitios web en los resultados de búsqueda de ChatGPT. Si lo bloqueas, tu sitio no aparecerá en respuestas de búsqueda de ChatGPT, aunque todavía podría aparecer como enlace navegacional en algunos casos. OpenAI recomienda permitirlo en robots.txt y también desde sus rangos de IP publicados. | Se controla con robots.txt usando | Permitirlo si quieres visibilidad como fuente o enlace en búsquedas dentro de ChatGPT. No basta con robots.txt: también hay que revisar que el WAF o la CDN no lo estén frenando. |
GPTBot | Es el bot de OpenAI usado para rastrear contenido que podría emplearse en el entrenamiento de modelos fundacionales (modelos base de IA). OpenAI indica que bloquearlo comunica que tu contenido no debe usarse para entrenamiento. | Se controla con robots.txt usando | Para un SaaS B2B con contenido propietario, documentación valiosa o contenido diferencial, lo más prudente suele ser bloquearlo por defecto y abrirlo solo si hay una decisión explícita de negocio. |
ChatGPT-User | Es un user-agent (identificador técnico que se envía en una solicitud web) que OpenAI usa para ciertas acciones iniciadas directamente por usuarios de ChatGPT o de Custom GPTs. No es crawling automático de la web. OpenAI indica que, como estas visitas nacen de una acción del usuario, las reglas de robots.txt pueden no aplicar. | No se gestiona igual que un crawler automático. Para Search y opt-outs automáticos, OpenAI indica usar OAI-SearchBot. Para este tipo de tráfico, el control práctico suele pasar por WAF, autenticación, permisos por endpoint o rate limits. | Trátalo más como tráfico similar al de un navegador que como un bot clásico de indexación. No asumas que robots.txt lo va a detener. |
Acerca de Framer:
¿Dónde se edita el archivo robots.txt en Framer?
En Framer, el archivo robots.txt se genera automáticamente para cada sitio web publicado. Puedes revisarlo agregando /robots.txt al final de tu dominio.
Configuración de meta tags y headers en Framer
Framer sí permite insertar meta tags (etiquetas dentro del HTML que dan instrucciones a buscadores y navegadores) y structured data (datos estructurados que ayudan a los buscadores a entender mejor el contenido). Esto se gestiona desde Project Settings → Custom Code, donde puedes elegir en qué parte del sitio se inserta el código y si aplica a todo el proyecto o solo a páginas específicas.
Si quieres controlar la indexación de una página concreta, Framer recomienda hacerlo con meta robots (instrucciones para buscadores dentro de la página). En Page Settings puedes desactivar “Show page in search engines” y, cuando vuelves a publicar, Framer añade la etiqueta <meta name="robots" content="noindex">. Esto sigue la recomendación de Google: para evitar que una página aparezca en resultados, lo correcto es usar noindex y no bloquear primero la URL en robots.txt.
Sobre los headers HTTP como X-Robots-Tag (instrucciones que se envían desde el servidor, no desde el HTML), Framer documenta la inserción de código en <head> y <body>, pero no documenta un control directo de cabeceras HTTP desde la plataforma.
¿Cómo verificar que el hosting o la CDN no estén bloqueando bots importantes en Framer?
Como Framer no expone un panel propio de WAF para gestionar bots, la verificación suele hacerse de forma operativa. Primero, conviene comprobar que robots.txt responda correctamente y devuelva un código 200 (respuesta exitosa del servidor). Segundo, si tienes una capa externa delante del sitio, como CDN o WAF, conviene hacer pruebas por user-agent (la identificación técnica que usa un bot al hacer una solicitud) y revisar los logs.
Explora más: →Visita nuestro artículo que explica cómo construir y lanzar tu sitio web con Framer. Aprenderás a sacarle provecho a esta herramienta no-code para que tu negocio destaque, ya sea B2B o B2C.
Acerca de Webflow:
Acceso y edición de robots.txt en Webflow
Webflow sí permite crear y editar el archivo robots.txt. Esto se hace desde Site settings → SEO → Indexing, y el archivo se publica en la raíz del dominio. También conviene recordar algo importante: robots.txt es público. Es útil para dar instrucciones a los bots, pero no sirve como mecanismo de seguridad para proteger contenido sensible.
Control nativo de bots de búsqueda y bots de IA de Webflow
Una ventaja de Webflow es que, además de editar robots.txt, también ofrece Traffic control toggles (interruptores dentro de la interfaz para permitir o bloquear grupos de bots conocidos). Estos controles están en Site settings → SEO → Indexing y pueden generar reglas automáticamente para categorías como Search engine crawlers y AI bots. Webflow incluye en esas listas nombres como Googlebot, OAI-SearchBot, GPTBot, ChatGPT-User, ClaudeBot y PerplexityBot.
Custom code para meta tags específicos en Webflow
Webflow permite añadir meta tags (etiquetas dentro del HTML que le dan instrucciones a buscadores y navegadores) tanto a nivel de sitio como a nivel de página. A nivel global, se hace desde Site settings → Custom code. A nivel individual, se hace desde Page settings → Inside <head> tag. Esto es útil cuando quieres seguir indexando una página, pero controlar cómo se muestra en Google.
Reglas en WAF/CDN y límites de Webflow-hosted
Si tu sitio en Webflow está detrás de un WAF o un CDN externo, hay un riesgo de que termine bloqueando bots legítimos. Cloudflare, por ejemplo, documenta reglas para permitir verified bots (bots verificados) usando el campo cf.client.bot, precisamente para evitar ese problema.
Sobre los headers HTTP (cabeceras técnicas que envía el servidor), Webflow sí ofrece custom security headers, pero esa función es solo para clientes Enterprise y está limitada a un conjunto concreto de headers, como x-frame-options, content-security-policy o strict-transport-security.
Acerca de WordPress:
Plugins recomendados para gestionar robots.txt en WordPress
En WordPress puedes encontrarte con dos tipos de archivo robots.txt:
Virtual: Lo genera WordPress automáticamente, aunque no exista un archivo físico en el servidor.
Físico: Es un archivo real que está guardado en la raíz del sitio (la carpeta principal del dominio).
La Yoast explica ambos escenarios. WordPress genera un robots.txt por defecto y, si creas uno desde Yoast, el plugin reemplaza esa versión por defecto y añade su propia configuración, incluida la referencia al sitemap (el archivo que ayuda a los buscadores a descubrir las páginas del sitio).
Además, Yoast incluye un File Editor dentro del panel de administración (Yoast SEO → Tools → File Editor) para editar robots.txt y, según el servidor, también .htaccess (un archivo de configuración usado en servidores Apache para definir reglas del sitio).
Plugins de seguridad o WAF en WordPress y cómo verificar que no bloquean bots de búsqueda
En WordPress es bastante común que un plugin de seguridad o un WAF termine limitando o bloqueando crawlers sin querer.
Wordfence documenta su sistema de Rate Limiting (una función que limita cuántas solicitudes puede hacer una misma fuente en un periodo de tiempo) y aclara que puedes decidir cómo tratar a los crawlers de Google, incluso dando acceso ilimitado solo a bots verificados mediante reverse DNS (PTR) (una comprobación técnica para validar que una IP realmente pertenece a Google).
Explora más: → Visita nuestro artículo sobre Framer vs WordPress para SaaS B2B. Aprenderás qué plataforma se adapta mejor a tu negocio según velocidad de ejecución, performance, marketing y capacidad de crecimiento.
Checklist de validación y monitoreo
Para founders y equipos de marketing de SaaS B2B, el estándar debería ser este: probar y observar antes de asumir que una configuración está funcionando bien.
Estos son algunos checks básicos para validar si un sitio alojado en Framer, Webflow, WordPress u otra infraestructura está bien preparado para aparecer en AI Overviews o en búsquedas dentro de agentes de IA generativa.
Validar cómo ve Google tu página
Google recomienda usar la herramienta URL Inspection (una función de Google Search Console que muestra cómo Googlebot ve una página) para revisar el HTML que recibió al rastrear la URL. Esto sirve para comprobar si los preview controls (controles que limitan o ajustan lo que Google puede mostrar, como snippets o previews) están visibles y configurados correctamente.
Validar el “carril OpenAI”
En el caso de OpenAI, la documentación indica que los cambios en robots.txt pueden tardar alrededor de 24 horas en reflejarse en sus sistemas de Search.
Además, si tu stack usa un WAF o una CDN, OpenAI recomienda permitir OAI-SearchBot en robots.txt y también permitir solicitudes desde sus rangos de IP publicados. Esto aumenta la probabilidad de que tu sitio pueda aparecer en resultados de búsqueda dentro de sus productos.
¿Cómo bloquear secciones de tu web?
Tu decisión puede resumirse así:
¿Quieres aparecer como fuente o enlace en experiencias con IA?
Sí → Mantén la indexación en Google y permite OAI-SearchBot.
No → Bloquea el crawling relevante. Ten en cuenta que eso puede sacarte del índice de Google y también excluirte de ciertos resultados en buscadores con IA.
¿Quieres evitar entrenamiento o grounding por parte de proveedores de IA?
Sí → Bloquea GPTBot y Google-Extended, sin tocar Googlebot.
No, o solo en algunos casos → Permite el acceso por rutas o según tu política editorial (por ejemplo, permitir el blog, pero bloquear documentación premium), y controla cuánto puede mostrarse con preview controls cuando haga falta.
¿Cómo Noodlesoup puede ayudarte?
Para un founder de SaaS B2B, el sitio web es una pieza central de autoridad y crecimiento. Es el lugar donde tu propuesta de valor se vuelve creíble para tus clientes potenciales y, ahora, también para los nuevos sistemas de descubrimiento impulsados por la IA generativa.
En Noodlesoup ayudamos a equipos que sienten que su sitio actual ya no refleja la calidad de su producto o no les da la agilidad que necesitan para evolucionar. En esos casos, podemos acompañarte a migrar tu web desde plataformas como WordPress o Webflow hacia Framer, construyendo una base más clara y más fácil de operar para marketing y negocio.
Y, si quieres crear un sitio web desde cero, también podemos diseñarlo y desarrollarlo en Framer, teniendo en cuenta una arquitectura clara, páginas estratégicas bien definidas, contenido que responde preguntas reales del buyer y una configuración técnica que favorezca la visibilidad en Google Search, AI Overviews y entornos de búsqueda dentro de asistentes y agentes de IA.
FAQs:
¿Qué pasa si no configuro nada y dejo los bots de IA como están?
Tu sitio puede seguir apareciendo en Google si cumple los fundamentos normales de SEO, pero también puedes estar permitiendo o bloqueando cosas sin darte cuenta. En OpenAI, además, la visibilidad en ChatGPT Search y el uso del contenido para entrenamiento se controlan por separado, así que conviene definir esa política de forma explícita.
¿Cómo decido qué partes de mi web abrir y cuáles proteger?
Abre las páginas que te ayudan a ser descubierto, como producto, comparativas, casos de uso o blog. Protege las partes más sensibles o diferenciales, como documentación privada, contenido premium o recursos internos. Google permite limitar cómo se muestra el contenido sin tener que cerrar toda la página, y OpenAI permite dejar visible tu sitio en ChatGPT Search sin autorizar entrenamiento.
¿Cómo sé si aparecer en Google o AI Overviews me está trayendo oportunidades?
Google incluye estas apariciones dentro del rendimiento general en Search Console, y recomienda unirlo con Analytics para ver qué visitas generan tiempo en sitio, formularios o demos.
Estrategias de branding y web para SaaS, directo a tu inbox
Un email semanal con lo que aprendemos trabajando con startups B2B. Sin relleno.
Acerca de nosotros
Acerca de nosotros
El estudio fue fundado en 2022 por Alejandro Duarte, diseñador multidisciplinario con más de 10 años de experiencia en la creación de productos digitales premiados y en colaborar con marcas de la Fortune 500. Junto a Sasha Briceño, directora creativa híbrida con formación en comunicación social que combina su pasión por las imágenes, el pensamiento estratégico y el storytelling, para crear universos de marca verbales y visuales consistentes. En Noodlesoup, somos un equipo apasionado por el buen diseño y comprometido con proyectos que tienen un propósito significativo. La colaboración, entre el equipo y con nuestros clientes, está en el corazón de todo lo que hacemos: es el umami* que nos caracteriza.
*Japonés: Conocido como el quinto sabor, es uno de los gustos básicos junto con el dulce, el ácido, el amargo y el salado. También significa sabroso.

